Platform Overview
Executive Summary
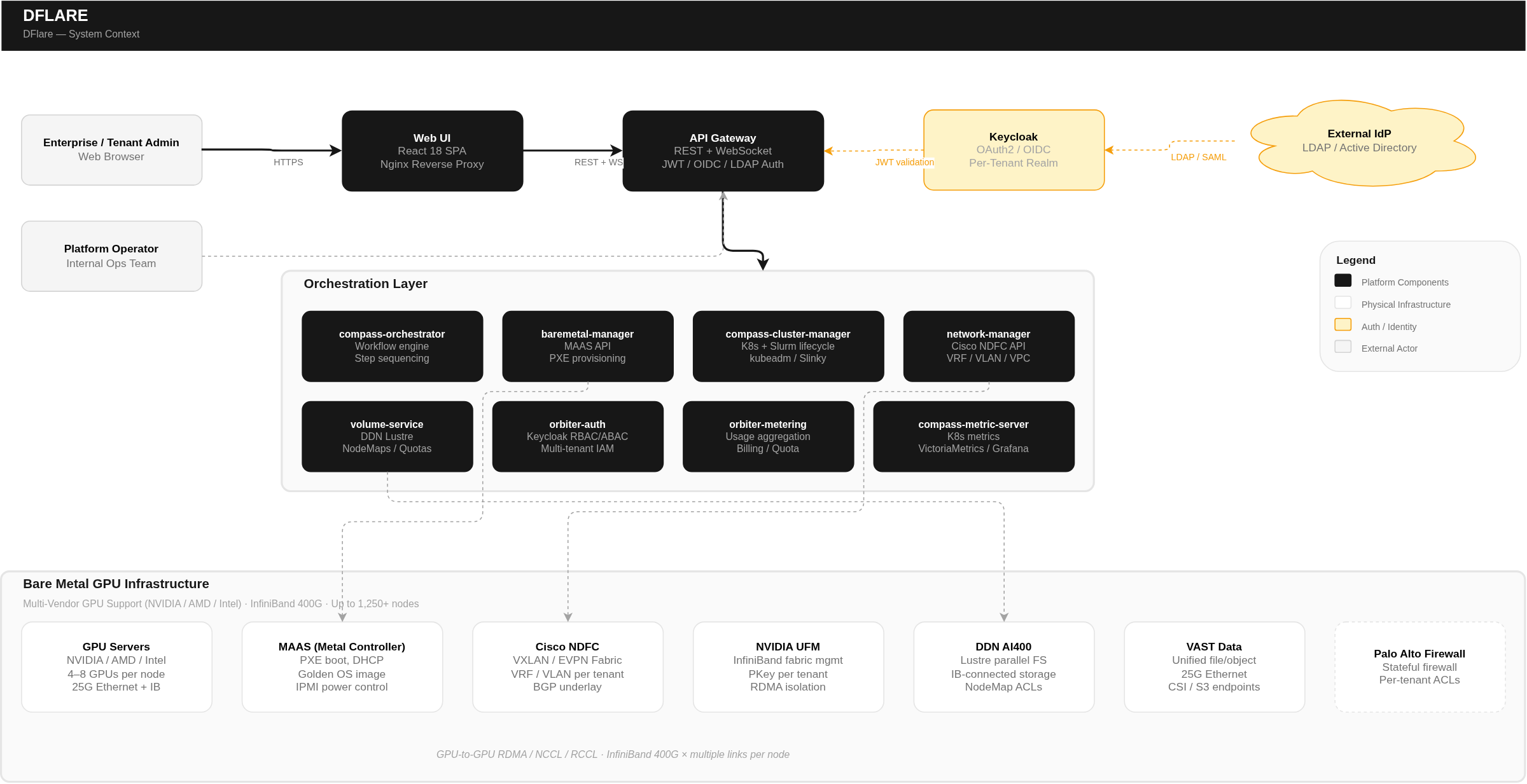
Dflare AI is a fully managed, enterprise-grade GPU-as-a-Service (GPUaaS) platform purpose-built for organizations running large-scale artificial intelligence, machine learning, and high-performance computing workloads. The platform transforms bare metal GPU servers into production-ready, multi-tenant compute environments — delivering the raw power of dedicated hardware with the operational simplicity of a managed cloud service.
From a single unified portal, enterprises can provision bare metal GPU nodes, orchestrate Kubernetes and Slurm (HPC) clusters, access high-performance InfiniBand-connected storage, run ML workloads through an integrated ML platform with notebooks and training jobs, enforce granular multi-tenant security, and track resource consumption with transparent usage-based billing — all without managing the underlying infrastructure complexity.
Built to support multi-vendor GPU architectures and interconnected via high-speed InfiniBand fabric backed by parallel storage, Dflare AI delivers the performance density required for frontier AI training, large language model fine-tuning, scientific simulation, and enterprise inference workloads — at scale, with isolation, and with full operational visibility.
Who It's For: Cloud service providers, sovereign AI programs, AI research institutions, enterprise AI teams, and any organization that needs dedicated GPU infrastructure without the operational burden of building and managing it from scratch.
The AI Infrastructure Challenge
The explosive growth of AI — particularly large language models, generative AI, and deep learning — has created unprecedented demand for GPU compute. Training a single frontier model can require thousands of GPUs running continuously for weeks. Inference at scale demands low-latency, high-throughput GPU clusters. Research teams need flexible, on-demand access to high-performance computing resources.
Yet building and operating GPU infrastructure at this scale is extraordinarily complex:
- Hardware Complexity: Modern GPU servers are not commodity hardware. Each node can contain multiple high-end GPUs interconnected via high-bandwidth links, multiple InfiniBand connections, specialized cooling, and significant power requirements per node.
- Multi-Tenancy is Hard: Serving multiple teams or customers from shared GPU infrastructure demands rigorous isolation — at the network level, the storage level, the identity level, and the compute level.
- Two Worlds — Containers & HPC: AI workloads span two operational paradigms. Data engineers prefer Kubernetes; research scientists prefer Slurm. Most platforms force a choice. Supporting both on the same infrastructure is a significant engineering challenge.
- Storage Performance: AI training workloads are data-hungry. A single training run can read terabytes of data. The storage system must deliver hundreds of gigabytes per second of aggregate throughput — far beyond what standard NAS or SAN can provide.
- Operational Overhead: Even after the infrastructure is built, the ongoing operational burden is substantial — monitoring GPU health, managing firmware, enforcing quotas, tracking resource consumption for billing, maintaining security compliance, and handling tenant lifecycle management.
What Dflare AI Solves
Dflare AI eliminates these challenges by delivering a fully integrated, automated platform that handles the entire lifecycle — from bare metal provisioning to workload execution — through a single pane of glass. Organizations get the performance of dedicated GPU hardware with the operational model of a managed service.
Eight Operational Pillars
Dflare AI is an end-to-end GPU infrastructure platform that automates eight critical operational pillars:
-
Bare Metal Provisioning — Takes physical GPU servers from powered-off to workload-ready automatically. Minutes to production, not weeks of manual setup.
-
Network Orchestration — Creates isolated tenant networks with VRFs, VLANs, and InfiniBand partitions. Every tenant gets their own secure, high-performance network.
-
Kubernetes Orchestration — Builds production-grade K8s clusters powered by CKP (Coredge Kubernetes Platform) with GPU operators, CNI, and monitoring.
-
Slurm (HPC) Orchestration — Deploys Slurm on Kubernetes via operator-based deployment for batch job scheduling. HPC users get familiar tools (sbatch, squeue) on modern infrastructure.
-
Storage Orchestration — Provisions high-performance parallel filesystem storage over InfiniBand + platform object storage. GPU nodes access training data at maximum fabric throughput.
-
Security & Access Control — Enforces RBAC + ABAC with enterprise IAM, per-tenant isolation at every layer. Zero-trust by design — no action is trusted by default.
-
Billing & Metering — Tracks GPU-hours, CPU-hours, storage, network — converts to billable records. Transparent, accurate, usage-based billing.
-
ML Platform — Provides an integrated machine learning environment with GPU notebooks, distributed training, LLM inference, fine-tuning, experiment tracking, and dataset management. Complete ML lifecycle in your workspace.
How It Works — At a Glance
A tenant administrator logs into the portal, creates a project, selects GPU nodes from available pools, and requests a cluster. The platform automatically provisions networking, installs the operating system, configures storage, bootstraps the cluster (Kubernetes or Slurm), deploys GPU runtime operators, enables monitoring, and begins metering — all without manual intervention.
Use Cases & Target Industries
Primary Use Cases
Large-Scale AI Model Training: Train frontier AI models across hundreds or thousands of GPUs. InfiniBand-connected nodes enable efficient multi-node distributed training with RDMA collective operations. Parallel filesystem delivers the storage throughput to keep GPUs fed with training data.
LLM Fine-Tuning & RLHF: Fine-tune large language models on proprietary datasets with dedicated GPU allocation, isolated storage, and job-level accounting. Slurm's fair-share scheduling ensures equitable access across research teams.
AI Inference at Scale: Deploy inference services on Kubernetes clusters with GPU resource requests, auto-scaling, and load balancing. Monitor GPU utilization and latency through integrated dashboards.
High-Performance Computing (HPC): Traditional HPC workloads — scientific simulation, computational fluid dynamics, molecular dynamics, climate modeling — run on Slurm with familiar batch scheduling.
MLOps & Experiment Management: Kubernetes-native workflows for ML pipelines, experiment tracking, and model serving. Persistent storage for datasets and model artifacts.
Target Industries
-
Cloud Service Providers — Offer GPU compute to their customers. Multi-tenant isolation, usage-based billing, scalability.
-
Sovereign AI Programs — National AI infrastructure. Air-gapped deployment, compliance, data sovereignty.
-
AI Research Institutions — Large-scale model training & experimentation. Slurm + K8s flexibility, fair-share scheduling, job accounting.
-
Enterprise AI Teams — Production ML pipelines and inference. Kubernetes-native, integrated monitoring, RBAC.
-
Healthcare & Life Sciences — Drug discovery, genomics, medical imaging AI. HIPAA alignment, tenant isolation, audit trails.
-
Financial Services — Risk modeling, fraud detection. Security, compliance, granular billing.
Key Differentiators
- Unified Kubernetes + Slurm on Shared Infrastructure: Most platforms force a choice between containers and HPC. Dflare AI runs both on the same bare metal nodes, with unified networking, storage, security, and billing.
- True Bare Metal Performance: No hypervisor overhead. No virtualization layer. GPUs are accessed directly by workloads with hardware-level BIOS and OS tuning pre-applied.
- Multi-Vendor GPU Support: Not locked into a single GPU vendor. Supports NVIDIA, AMD, and Intel accelerators — giving organizations flexibility to choose the best GPU for their workload.
- Hardware-Enforced Multi-Tenant Isolation: Tenant isolation enforced at InfiniBand switch hardware level (partition key), filesystem level (access control map), and network fabric level (VRF/VXLAN). Double isolation on storage ensures defense-in-depth.
- High-Throughput Storage at Fabric Speed: Parallel filesystem over multiple high-bandwidth InfiniBand links per node delivers storage throughput that matches the compute appetite of modern GPUs.
- Transparent, Granular Billing: Metering at configurable intervals from hardware-level exporters. Every GPU-hour, CPU-hour, and storage byte is tracked, correlated to tenant/project/user, and converted to auditable billing records.
- Automated End-to-End Lifecycle: From bare metal power-on to production-ready cluster — fully automated. No SSH, no manual configuration, no ticket-based provisioning.
- Enterprise Security by Default: Zero-trust architecture with RBAC + ABAC, per-tenant IAM realms, short-lived JWT tokens, MFA, mTLS, and comprehensive audit logging. Aligned with NIST, ISO 27001, and HIPAA frameworks.