Slurm (HPC) Cluster Orchestration
Business Value: Give HPC and research teams the Slurm experience they know — sbatch, squeue, srun — running on modern, Kubernetes-managed infrastructure with enterprise security and billing.
How It Works
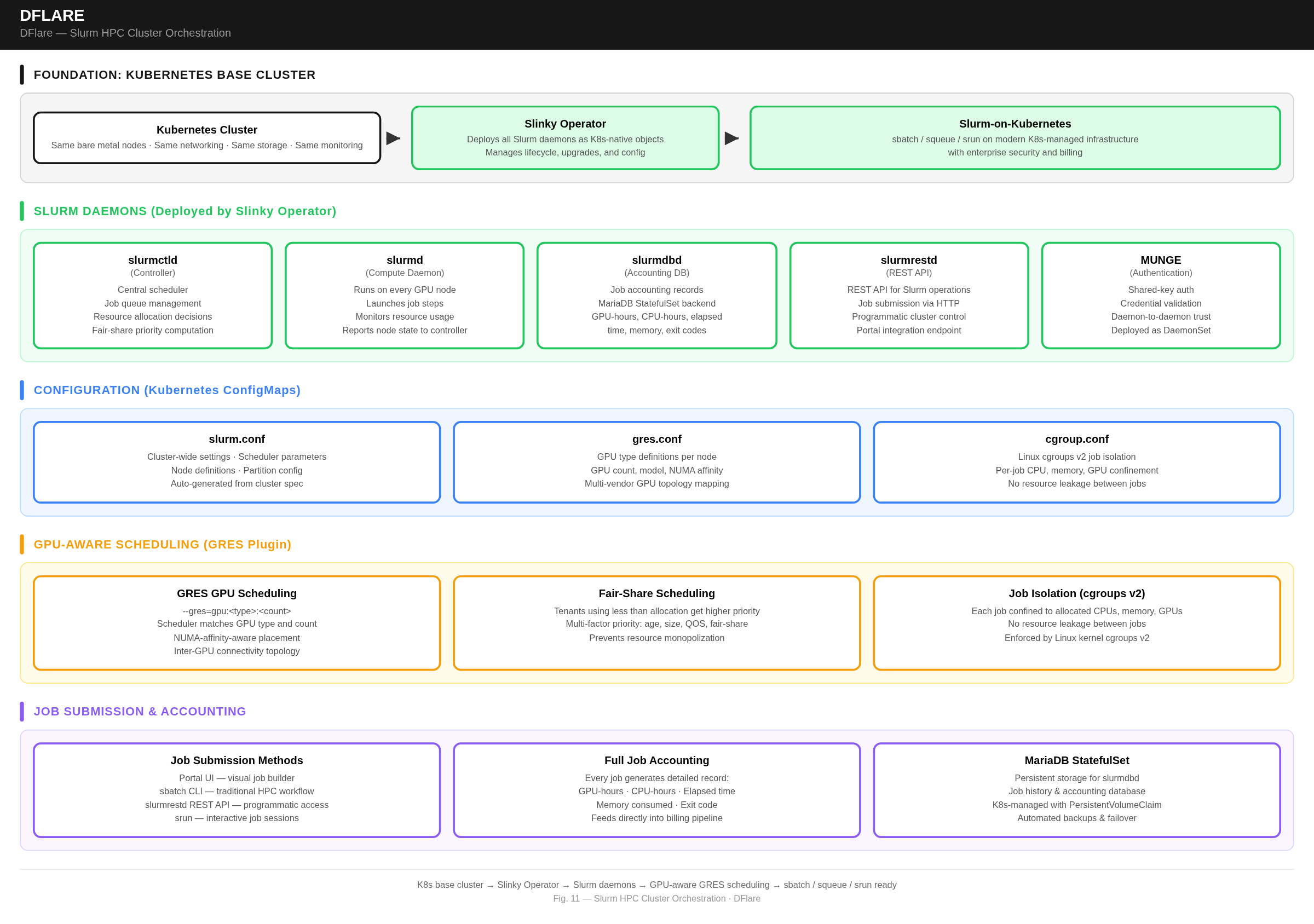
Dflare AI runs Slurm on top of Kubernetes using a Kubernetes-native operator. The platform first builds a complete Kubernetes cluster, then layers Slurm on top as Kubernetes-native objects:
- The operator deploys all Slurm daemons: slurmctld (controller), slurmd (compute daemon on every GPU node), slurmdbd (accounting database), slurmrestd (REST API), and MUNGE (authentication)
- Configuration files — slurm.conf, gres.conf, cgroup.conf — are auto-generated from the cluster spec and distributed as Kubernetes ConfigMaps
- A relational database runs as a StatefulSet with persistent storage for job accounting
- GPU-aware scheduling via GRES plugin: Slurm understands GPU topology, NUMA affinity, and inter-GPU connectivity for optimal multi-GPU job placement across supported GPU vendors
Technical Highlights
- Unified infrastructure: same bare metal nodes, same networking, same storage, same monitoring — whether running K8s or Slurm workloads
- GPU-aware scheduling:
--gres=gpu:<type>:<count>tells the scheduler exactly which nodes have the right GPU type and count available - Job isolation via Linux cgroups v2: each job is confined to its allocated CPUs, memory, and GPUs — no resource leakage between jobs
- Fair-share scheduling: tenants who have used less than their allocation get higher job priority
- Full job accounting: every completed job generates a detailed record — GPU-hours, CPU-hours, elapsed time, memory consumed, exit code — feeding directly into the billing pipeline
- Job submission via portal UI, sbatch CLI, or REST API